Entrenamiento y pérdida
Machine LearningMay 10, 2018
Entrenar un modelo simplemente significa aprender (determinar) valores correctos para todas las ponderaciones y las ordenadas al origen de los ejemplos etiquetados. En un aprendizaje supervisado, el algoritmo de un aprendizaje automático construye un modelo al examinar varios ejemplos e intentar encontrar un modelo que minimice la pérdida. Este proceso se denomina minimización del riesgo empírico.
La pérdida es una penalidad por una predicción incorrecta. Esto quiere decir que la pérdida es un número que indica qué tan incorrecta fue la predicción del modelo en un solo ejemplo. Si la predicción del modelo es perfecta, la pérdida es cero; de lo contrario, la pérdida es mayor. El objetivo de entrenar un modelo es encontrar un conjunto de ponderaciones y ordenadas al origen que, en promedio, tengan pérdidas bajas en todos los ejemplos. Por ejemplo, la Figura 3 muestra un modelo al lado izquierdo con una pérdida alta, y al lado derecho un modelo con pérdida baja. Ten en cuenta lo siguiente con respecto a la imagen:
- La flecha roja representa la pérdida.
- La línea azul representa las predicciones.
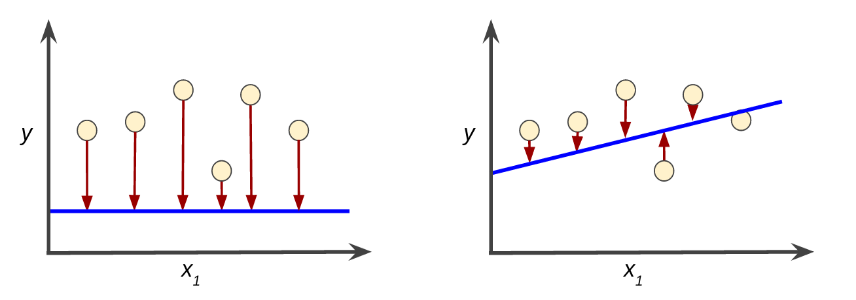
Figura 3. Pérdida alta en el modelo de la izquierda; pérdida baja en el modelo de la derecha.
Ten en cuenta que las flechas rojas en la figura izquierda son mucho más largas que las de la figura derecha. Claramente, la flecha azul en la figura de la derecha es un modelo de predicción mucho más acertado que la flecha azul en la figura de la izquierda.
Tal vez te preguntes si puedes crear una función matemática (una función de pérdida) que sume las pérdidas individuales de una forma que tenga sentido.
Pérdida al cuadrado: Una función popular de pérdida
Los modelos de regresión lineal que se examinan aquí usan una función de pérdida llamada pérdida al cuadrado(también conocida como pérdida L2). A continuación, se muestra la pérdida al cuadrado para un único ejemplo:
= the square of the difference between the label and the prediction
= (observation - prediction(x))2
= (y - y')2
El error cuadrático medio (ECM) es el promedio de la pérdida al cuadrado de cada ejemplo. Para calcular el ECM, sumamos todas las pérdidas al cuadrado de los ejemplos individuales y, luego, lo dividimos por la cantidad de ejemplos:

donde:
- (x,y) es un ejemplo en el que
- x es el conjunto de atributos (p. ej., temperatura, edad y éxito para aparearse) que el modelo usa para realizar las predicciones.
- y es la etiqueta del ejemplo (p. ej., cantos por minuto).
- prediction(x) es un atributo de las ponderaciones y las ordenadas al origen en combinación con el conjunto de atributos x.
- D es el conjunto de datos que contiene muchos ejemplos etiquetados, que son los pares (x,y).
- N es la cantidad de ejemplos en D.
Si bien MSE se usa comúnmente en el aprendizaje automático, no es la única función de pérdida práctica ni la mejor para todas las circunstancias.

William Arevalo
Data Scientist • Bogotá, CO • willarevalo.developer@gmail.com
Passionate Data Scientist | Scrum amateur | Pentester | Services Admin | Calisthenics devotee