Reducción de la pérdida: un enfoque iterativo
Machine LearningMay 10, 2018
En el módulo anterior, se presentó el concepto de pérdida. Aquí, aprenderás cómo un modelo de aprendizaje automático reduce la pérdida de manera iterativa.
Es posible que el aprendizaje iterativo te recuerde el juego infantil en el que los objetos estaban fríos o calientes (cerca o lejos) al intentar encontrar un elemento escondido, como un dedal. En este juego, el “objeto escondido” es el mejor modelo posible. Primero te arriesgarás a adivinar (“El valor de W1 es 0”.) y esperarás a que el sistema te indique cuál es la pérdida. Luego, intentarás adivinar otra vez (“El valor de W1 es 0.5”.) y verás cuál es la pérdida. Bien, ya estás más cerca. En realidad, si juegas a este juego correctamente, por lo general siempre estarás más cerca. El verdadero truco del juego es intentar buscar el mejor modelo posible de la manera más eficaz posible.
La siguiente figura sugiere el proceso iterativo de prueba y error que usan los algoritmos de aprendizaje automático para entrenar un modelo:
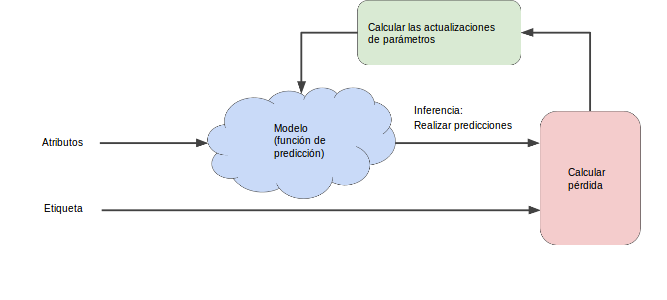
Figura 1. Un enfoque iterativo para entrenar un modelo.
Usaremos este mismo enfoque iterativo durante todo el Curso intensivo de aprendizaje automático y detallaremos distintas complicaciones, particularmente dentro de la tormentosa nube azul. Las estrategias iterativas prevalecen en aprendizaje automático, principalmente debido a que se ajustan muy bien a la escala de los conjuntos de datos de gran tamaño.
El “modelo” toma uno o más atributos como entrada y devuelve una predicción (y’) como resultado. Para simplificar, considera un modelo que toma un atributo y devuelve una predicción:

¿Qué valores iniciales deberíamos establecer para B y W1? Para la regresión lineal, los valores de inicio no son importantes. Podríamos elegir valores al azar, pero tomaremos los siguientes valores triviales en su lugar:
B = 0
W1 = 0
Supón que el primer valor del atributo es 10. Al vincular ese valor con el atributo de predicción, se obtiene lo siguiente:
y’ = 0 + 0(10)
y’ = 0
La parte de “Cálculo de pérdida” del diagrama es la función de pérdida que usará el modelo. Supón que usamos la función de pérdida al cuadrado. La función de pérdida incorpora dos valores de entrada:
y’: la predicción del modelo para los atributos x
y: la etiqueta correcta correspondiente a los atributos x.
Finalmente, llegamos a la parte de “Actualizar parámetros” del diagrama. Aquí, el sistema de aprendizaje automático examina el valor de la función de pérdida y genera valores nuevos para B y W1. Por el momento, simplemente supón que el cuadro verde misterioso traza valores nuevos y, luego, el sistema de aprendizaje automático vuelve a evaluar todos esos atributos con todas las etiquetas; se obtiene un nuevo valor para la función de pérdida, que genera valores de parámetros nuevos. El aprendizaje continúa iterando hasta que el algoritmo descubre los parámetros del modelo con la pérdida más baja posible. En general, iteras hasta que la pérdida general deja de cambiar o, al menos, cambia muy lentamente. Cuando eso ocurre, decimos que el modelo ha convergido.
Punto clave:
Un modelo de aprendizaje automático se entrena comenzando con una hipótesis inicial para los pesos y sesgo, y de manera iterativa ajustar esas hipótesis hasta que se aprenden las ponderaciones y ordenadas al origen con la pérdida más baja posible.

William Arevalo
Data Scientist • Bogotá, CO • willarevalo.developer@gmail.com
Passionate Data Scientist | Scrum amateur | Pentester | Services Admin | Calisthenics devotee